


In the early days of computing, vendors sold software, including compilers
and operating systems, as part of the hardware they ran on. That
changed in 1974, when the US Commission on New Technological Uses of
Copyrighted Works (CONTU) decided that computer programs were subject to
copyright, creating a market for what were initially called “program
products.” Despite the resistance movement of the Free Software Foundation
and open source, there was, and is, a clear market for commercial software
products. “Build versus buy” decisions are everywhere today, and rightly so.
Building software is risky and expensive, and software product companies can
spread that risk and expense across multiple customers.
However, as you may have guessed by the title of this article, such
decisions don’t apply to all contexts.
You can’t buy integration
Despite a wide range of tools that aim to simplify wiring systems
together, you can’t buy integration.
You can buy programming languages. After the 1974 CONTU ruling, it
became common to pay for the compiler. Bill Gates’ famous Open
Letter To Hobbyists was a clarion call for the community to pay for
Micro-Soft’s Altair BASIC interpreter (they dropped the dash in later
years). The Free Software Foundation’s GCC compiler opened the door to the
commoditization of programming languages but left open a commercial market
for developer tooling. I’m happy to program in Java for example — now
freely available — but I would not be excited to do so in vi or
Notepad.
Integration software products — ESBs, ETL tools, API platforms, and
cloud integration services — are not products that directly solve a
business problem. They are not in the same category, for example, as fraud
detection products or analytics products or CRMs. They are programming
languages, bundled with a toolchain and a runtime to support the
compilation process. When you buy an integration product, you are agreeing
to build the integration itself in a commercial programming language.
Integration tools are almost always low-code platforms, which means
they aim to simplify the development effort by providing a graphical
design palette you can drag and drop integration workflow on top of. The
source code is typically saved in a markup
language that can be interpreted by the runtime. You might drag and drop
some workflow onto a palette, but underneath the hood, the platform saves
the source code as JSON or XML, and embeds a runtime that knows how to
interpret the markup into actual machine code, no different than
Micro-Soft’s early compiler knew how to convert BASIC code into machine
code on the Altair platform. For example, here is the “Hello, World”
source code for Step Functions, an AWS orchestration engine:
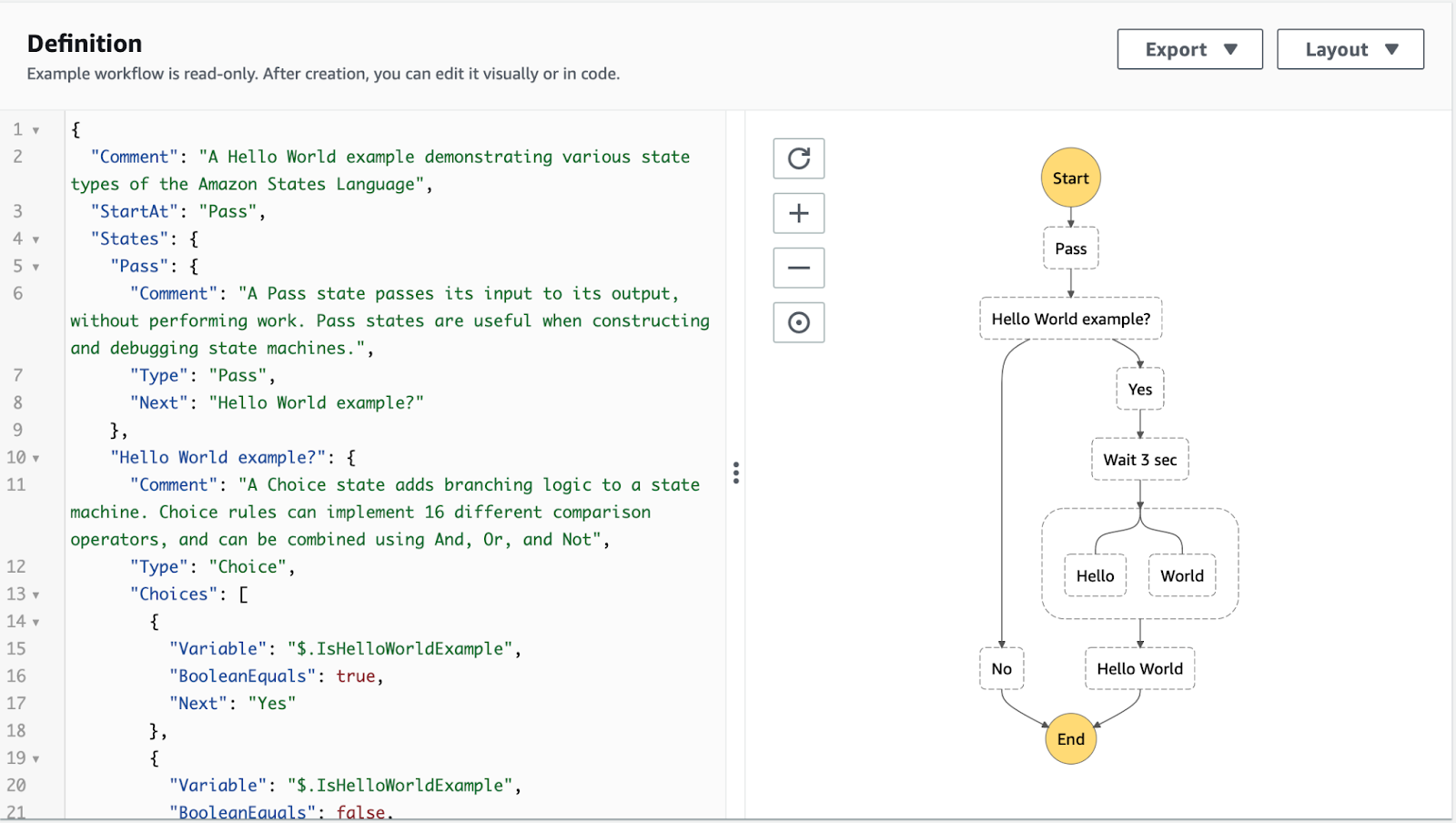
Figure 1: Step Functions represents a workflow
with both JSON and graphical design palette
Many integration tools, including AWS Step Functions, let you program
using either the graphical palette or the markup language directly. While
the palette is often preferred for reasons obvious to anyone who read
Charles Petzold’s famous
April Fools joke about CSAML, the complexity of
configuring integration steps in the palette means that, in practice,
competent developers gain some facility with the underlying markup
language itself. In effect, there is a bidirectional mapping from the
graphical palette to the markup language such that changing one can
immediately be reflected in the other. If I’ve understood the vernacular
of mathematics correctly, that’s what’s called an
isomorphism, so I’ll
call the resulting structure “source-diagram isomorphism,” where both the
palette and the markup language represent source code and can be
seamlessly translated back and forth. That of course represents a
developer-centric view of the world; the runtime itself only cares about
the markup language.
This is quite different from most software programming, where the developer
directly edits the source code absent a graphical palette, a practice I’ll call
“source
endomorphism,” although you can also call it “normal” if that’s easier
to remember. There are tools, of course, that visualize class diagrams in Java
and perhaps even let you make edits that are reflected back in the source code,
but the usual activity of a Java developer is to directly edit Java source code
in an IDE.
The advantage of providing a graphical design palette is that it provides a
way of organizing thought, a
domain specific language (DSL) for integration
problems, allowing you to focus on the narrow problem of wiring systems together
absent extraneous complexity. Java may be better at solving general purpose
problems, but the constraints of the design palette and declarative markup
language purport to solve integration and workflow concerns more elegantly, in
the same way that Excel functions let you solve a budgeting problem more
elegantly than writing custom Java code. Similarly, in a number of contexts, I’d
much prefer the calculator on my iPhone over the impressive
HP 50g graphic calculator, with its support for Reverse Polish Notation and
scientific calculations.

Figure 2: A good DSL removes complexity by focusing on the core problem
When you buy integration tools, you are agreeing to build the actual
integration itself. What you are buying is a promise that the integration
can be solved more efficiently and more simply than using a general
purpose language. The job of the architect then comes down to
understanding in what contexts that promise is likely to hold true, and
to avoid the understandable temptation to convert the “buy” decision into
a mandate to use the tool outside of those contexts in order to justify its
ROI.
Some integration DSLs are simpler projections of the problem space,
like my iPhone calculator. Others are indeed Turing complete, meaning, in
a theoretical sense, they have the same algorithmic power as a general
purpose language. While true, academic discussions of computability fail
to account for software engineering, which a
group of Googlers defined as
“programming over time.” If programming requires working with abstractions, then programming
over time means evolving those abstractions in a complex ecosystem as the environment
changes, and requires active consideration of team agreements, quality practices, and
delivery mechanics. We’ll examine how
programming-over-time concerns affect integration in more detail shortly and how
they inform the appropriate contexts for low-code integration tools. First, though, I
want to challenge the idea that the primary goal of integration is wiring systems
together, as I believe a broader definition allows us to better segregate the parts
of the ecosystem where simplifying abstractions facilitate programming and where
the additional complexity of programming-over-time concerns requires a general purpose
programming language, a claim I’ll defend shortly.
Put most of your energy into building clean interfaces
For most people, the word
“integration” creates the impression of connecting systems together, of
sharing data to keep systems in sync. I believe that definition of
integration is insufficient to meet the demands of a modern digital
business, and that the real goal of integration done well is to create
clean interfaces between capabilities.
When our primary focus is connecting systems, we can measure how
successful our integration approach is by how quickly we can wire
a new system into an existing technical estate. The systems
become the primary value driver inside that estate, and integration becomes
a necessary evil to make the systems behave properly. When instead we
shift our primary focus to creating clean interfaces over digital
capabilities, we measure success by increasing digital agility over time,
and those digital capabilities become the primary value driver, arguably
even more important than the systems themselves. There’s a lot to unpack
in that difference, starting with the emphasis on interface over
implementation.
Digital organizations shift the primary focus of integration
from the systems to the capabilities, emphasizing clean
interfaces over those capabilities.
Simplifying interfaces are one of the critical elements in creating a
successful product and to scaling inside a complex ecosystem. I have very
little understanding of the mechanical-electrical implementation
underlying the keyboard I’m typing on, for example, or the input system
drivers or operating system interrupts that magically make the key I’m
typing show up on my screen. Somebody had to figure that all out — many
somebodies, more likely, since the keyboard and system driver and
operating system and monitor and application are all separate “products” — but
all I have to worry about is pressing the right key at the right
time to integrate the thoughts in my brain to words on the screen.
That, of course, has an interesting corollary: the key (no pun
intended) to simplifying the interface is to accept a more complex
implementation.
There is nothing controversial about that statement when we think of
digital products that face off with the market. Google search is
unimaginably complex underneath the hood and uncannily easy for even a
digitally unsavvy user to use. We also accept it for digital products that
face off with business users. The sales team excited about bringing in
Salesforce surely understands that, while the user interface may be more
intuitive for their needs than the older CRM, it requires a significant
amount of effort to maintain and evolve the product itself, which is why
the subscription fees feel justifiable. Yet we treat integration
differently. Intuitively, we understand that the two-dimensional boxes on
our architecture diagrams may hide considerable complexity, but expect the
one-dimensional lines to be somehow different.
(They are different in one regard. You can buy the boxes but you can’t
buy the lines, because you can’t buy integration.)
While we have historically drawn up our project plans and costs around
the boxes — the digital products we are introducing — the lines are the
hidden and often primary driver of organizational tech debt. They are the
reason that things just take longer now than they used to.
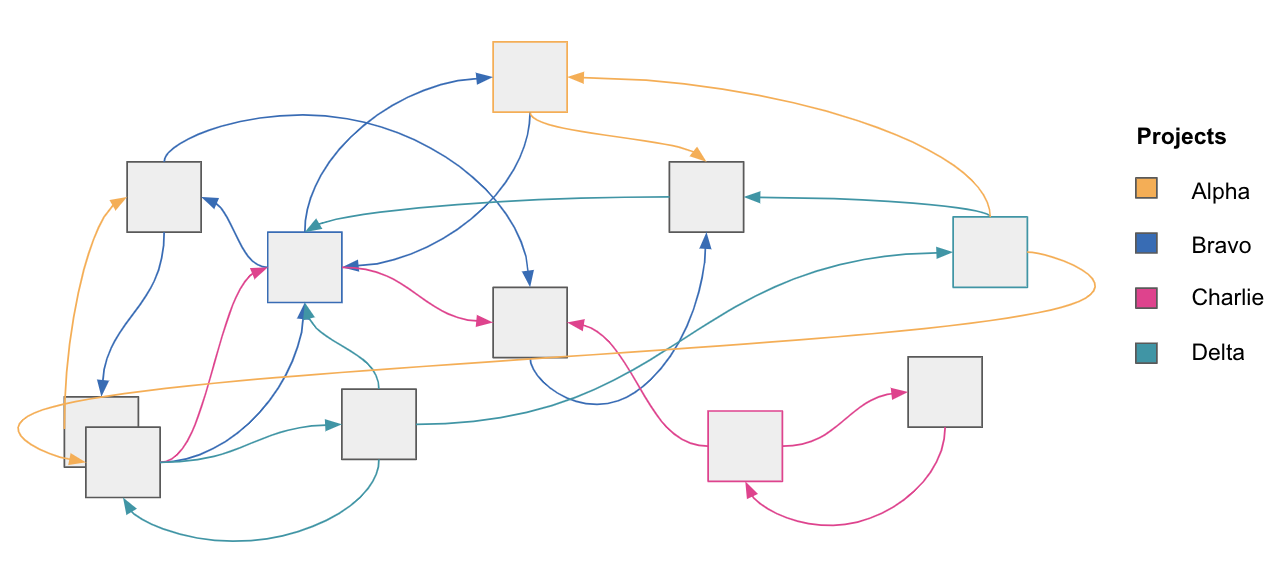
Figure 3: We think of projects in terms of the
applications they introduce, but the lines between those applications become
the critical cost driver over time
Simplifying that glue code is certainly a noble effort, and integration
tools can help, but not at the expense of building
clean interfaces over capabilities. Importantly, the only effective judges
of how easy an interface is to use are the actual users of it. Google
could have asked us for more information to make their search
implementation easier — geographical, recency, and popularity
information, for example — but instead they offered only a single text
box to type a search in and had to learn how to apply those factors into
their algorithm. The same concern applies to API design (which I define
broadly to include synchronous calls and asynchronous events).
Clean interfaces hide implementation details, and one of those
implementation details in integration contexts is the choice of
programming language. I have yet to see an architecture diagram that puts
the primary focus on the programming languages of the systems
involved:
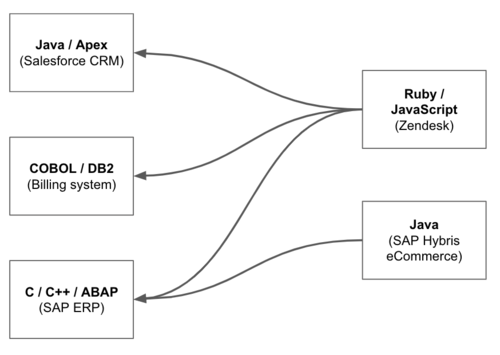
Figure 4: Emphasizing the implementation
languages in architecture diagrams is unusual
Yet I have seen all too many variations of diagrams that do exactly
that for integration. Such a view reinforces
a tactical understanding of integration as wiring systems together, as
it emphasizes the wiring toolchain instead of the digital capabilities.
Another implementation detail our API consumers would be happy to not
care about is which systems the data comes from. Outside of the
business users who work in SAP and the IT staff surrounding them, nobody
in your organization should have to care about the quirks of the SAP
system. They only care about how to get access to customer data or how to
create an order. That observation is worth calling out separately, as it
is one of the most commonly violated principles I see in integration
strategies, and one of the strongest indicators of an implicit philosophy
of integration as wiring systems together instead of creating clean interfaces
over digital capabilities. You don’t need an SAP API, because your API users don’t care
about SAP, but you might need an order management API. Abstract the
capability, not the system.
Your users don’t stand still, and quite often good APIs add value
through reuse. It’s easy to over-index on reuse as a primary goal of APIs
(I believe taming complexity is a more important goal) but it’s still a
useful aspiration. Keeping up with your users’ evolving needs means
breaking previous assumptions, a classic programming-over-time concern.
Carrying on with my previous metaphor, the job of a keyboard is to
seamlessly integrate its users thoughts into on-screen text. As a native
English speaker, I’ve never had to struggle with the
Pinyin transliteration
that native Chinese speakers have to, but for several
years I unnecessarily tortured myself by typing in the
Colemak keyboard
layout. Because my physical keyboard was incapable of magically adapting
to the software layout, there was an impedance mismatch between the
letters on the keyboard and what showed up on screen. Normally, that’s not
a problem: as a (not particularly fast) touch typist, I’m used to not
looking at the keyboard. However, that impedance mismatch made the
learning process painfully difficult as I constantly had to look at an
on-screen mapping to QWERTY and look down at the keys while my brain
worked through the resultant confusion. I’m sure there are keyboards out
there that are backlit and project the letter on the physical key in
consonance with the keyboard layout. The price of that improved interface,
of course, is more implementation complexity, and that evolution is a
programming-over-time concern.
Integration interfaces that fail to adapt to users over time, or that
change too easily with the underlying systems for implementation
convenience, are point-in-time integrations, which are really just
point-to-point integrations with multiple layers. They may wear API clothing,
but show their true stripes every time a new system is wired into the estate
and the API is duplicated or abused to solve an implementation problem.
Point-in-time integrations add to inter-system tech debt.
Treating integration as primarily about systems results in a
landscape littered with point-in-time integrations, decreasing
organizational agility.
Of course, your creaking systems of record will resist any attempt to
put them in a box. The ERP was specifically designed to do everything, so
trying to externalize a new capability that still has to integrate with
the ERP will be a challenge. It can require significant architectural
skill to contain the resulting integration complexity and to hide it from
the user, but the alternative is to increase your organizational tech
debt, adding another noodle to the spaghetti mess of point-to-point or
point-in-time integrations. The only way I’m aware of to pay that tech
debt down is to hold the line on creating a clean interface for your users
and create the needed transformations, caching, and orchestration to the
downstream systems. If you don’t do that, you are forcing all users of the
API to tackle that complexity, and they will have much less context than
you.
We need to invert the mindset, from thinking of how to solve
integration problems with our tools to instead thinking of how to build
the right interfaces to maximize agility.
Use a general purpose language to manage the interface evolution
Many commercial integration tools market their ability to own the
integration landscape and call out to general purpose languages as needed. While I
can appreciate the marketing behind such messaging — it promotes product
penetration and lock-in — as architectural guidance, it is exactly
backwards. Instead, we should almost always manage the interface evolution
in a general purpose language for at least two reasons: so we can better
manage the complexity of maintaining a clean interface, and so that we
avoid the gravitational pull of our tool’s mental model when making
strategic integration decisions.
General purpose languages excel at programming over time
Programming over time means making changes to source code over time,
and this is one area where source-diagram isomorphism pales in
comparison to normal development. The ability to “diff” changes between
source code commits is a developer superpower, an invaluable debugging
technique to understand the source of a defect or the context behind a
change. Diffing the markup source code language of an integration tool
is much harder than diffing Java code for at least three reasons:
modularity, syntax, and translation.
Normally, the developer is in charge of the modularity of the source
code. It is of course possible to throw all logic into a single file in
Java — the classic
God object — but competent developers create clean
boundaries in an application. Because they edit the textual source code
directly, those module boundaries of the language correspond to
filesystem boundaries. For example, in Java, packages correspond to
directories and classes to files. A source code commit may change a
number of lines of code, but those lines are likely to be localized to
natural boundaries in the code that the team understands. With
integration DSLs, the design palette has some control over the
modularity of the underlying textual source code, the price you pay for
source-diagram isomorphism. It is not uncommon to create, for example,
the entire workflow in one file.
Similarly the markup language itself may consist of syntax that makes
diffing harder. The good news is that the tools I’ve looked at do a good
job of “pretty printing” the markup language, which adds line endings to
make diffing easier. However, structural changes in a workflow are still
more likely to cause, for example, a re-ordering of elements in the
markup language, which will make a diff show many more lines of code
changed than such an operation might intuitively warrant. Additionally, some
languages, XML in particular, add a significant amount of noise,
obscuring the actual logic change.
Finally, because you are programming at a higher level of abstraction
in integration DSLs, you have a two step process to examine a diff.
First, as you would with Java, you have to understand the changed lines
in the context of the commit itself. With Java, since that source code
is the same source code you edit, the understanding stops there. With an
integration DSL, you have to make the additional mental leap of
understanding what those changed lines of markup mean to the overall
workflow, effectively mentally mapping them to what you would see on the
design palette. The delta between source code commits can only be
represented textually; graphical palettes are not designed to represent
change over time. The net effect of all of this is to increase the
cognitive load on the developer.
Gregor Hohpe has a brilliant story demonstrating the debuggability
shortcomings of low code platforms. In
The Software Architect Elevator,
he describes his experience when vendors shop their wares at his
company. Once they’ve shown how simple it is to drag and drop a solution
together, he asks the technical sales person if she could leave the room
for two minutes while Gregor tweaks something randomly in the underlying
markup language so he could then see how she debugs it when she comes
back in. So far, at least as of the publication of the book, no vendor
has taken him up on his offer.
Commercial integration DSLs also make it harder to scale
development within the same codebase. Not only is it harder to
understand the context of changes over time for a single source file,
it’s also harder to have multiple developers edit the same source file
in parallel. This isn’t pain-free in a general purpose language, but is
made possible by direct developer control over the modularity of the
source code, which is why you rarely see teams of only one or two Java
developers. With integration DSLs, given the constraints of source code
modularity and the additional mental leap it takes to understand the
source code — the markup source itself and the graphical workflow
abstractions they represent — merging is considerably more painful.
With such tools, it is quite common to constrain parallel development on
the same codebase, and instead break the problem down into separate
components that can be developed in parallel.
Programming over time requires advanced testing and environment
promotion practices. Many integration tool vendors go out of their way
to demonstrate their support for such practices, but once again, it is
an inferior developer experience. Each test run, for example, will
require spinning up the runtime that interprets the XML source code into
machine code. In practical terms, that friction eliminates the
possibility of short test driven development “red, green, refactor”
feedback loops. Additionally, you will likely be limited to the vendor’s
framework for any type of unit testing.
The ecosystems with general purpose programming languages evolve at a
rapid clip. Advances in testing tools, IDEs, observability tools, and
better abstractions benefit from the sheer scale of the community such
languages operate in. Low-code platforms have much smaller ecosystems,
limiting the ability to advance at the same pace, and the platform
constraints will almost certainly force developers to use toolchains
provided by the vendor to write and test code. That naturally has
implications for security concerns like supply chain and static analysis
scans. Such tooling gets a lot of attention for, say, Java open source libraries,
but far less attention in the walled gardens of the low-code world.
Finally, integration tools offer comparatively impoverished
operational support in their runtimes. Whereas observability tooling and
resiliency patterns get a lot of attention for general purpose
programming languages and the platforms that support them, those are
not the main focus of integration tools. I’ve seen multiple large-scale
adoptions of low code integration tools result in considerable
performance concerns, a problem that grows worse over time. It is
usually addressed initially by additional licensing costs, until that
too becomes prohibitive. Unfortunately, by that point, there is
significant platform lock-in.
Low-code tools are insufficient to handle the same type of complexity
that general purpose programming languages can handle. A colleague of
mine described a contentious environment where he was dealing with a
mandate to use TIBCO BusinessWorks, a well-known commercial integration
tool. He challenged the TIBCO team to a bake-off: he would send his best
Java / Spring developer to create an integration to another COTS
product’s web services — SOAP interfaces coded in Apache Axis — and they
could bring their best TIBCO developers to do the same. The Java
developer had a working implementation by lunch. The TIBCO team
discovered that the tool did not support the older version of Apache
Axis used by the COTS product, the type of legacy complexity common
in large enterprises. Following the mandate would have meant
going back to the vendor and changing their roadmap or adding an
extension in a general programming language. Fred Brooks called such
extensions “accidental complexity” in his famous
No Silver Bullet essay:
they add complexity due to the choice of solution, and have nothing to
do with the problem. Every mandate to use low-code tools for all
integration will accrue significant accidental complexity.
Even more concerning than the accidental complexity needed to run all
integration through commercial tooling, though, is the way such a
mandate puts the emphasis on implementation over interface, on systems
over capabilities.
Integration tools “think” in terms of implementation
Integration tools were created, and continue to thrive today, because
of the complexity of unlocking data and capabilities across the spectrum
of IT systems. Your actual customer master data may reside within, for
example, SAP, but the early part of a customer’s lifecycle exists in a
Siebel CRM. The IBM mainframe system still handles core billing for some
customers; an Oracle ERP for others. Now the business wants to replace
Siebel with Salesforce. The business team bringing in a new product
naturally understands that it will take some time to get the
configuration right for adapting it to their sales intake process, but
the last thing any of them want is to be told of long IT timelines just
to sort out the glue between systems. It’s SaaS, after all!
Traditionally, those long timelines were the result of point-to-point
integration, which did not allow for learning. Every new wire between
systems meant teams had to re-learn how to connect, how to interpret the
data, how to route between systems, and so on. Integration tools broke
the problem down into smaller pieces, some of which could be reused,
especially the connectivity into systems. Take a look at some of the
actions available on the AWS Step Functions palette we looked at
earlier:
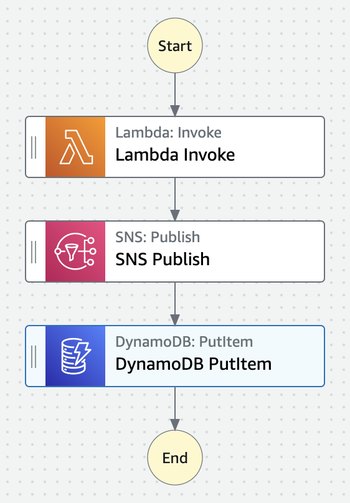
Figure 6: Each step in an AWS Step
Functions workflow describes an implementation concern
Step Functions describes all of the actions in terms of some action
on some AWS
service. You can configure each box in the workflow to describe, for
example, the DynamoDB table name, allowing you to focus on the overall
flow in the main part of the palette. While Step Functions is a
relatively new integration tool with an obvious bias towards cloud
native AWS services, all integration tools that I’m familiar with tend
to work along similar lines with their focus on implementation concerns.
The early on-prem equivalents for application integration were
enterprise service buses (ESBs), which separated out system connectivity
as a reusable component from orchestration and routing. You can see that
separation in a simplified view of
Mulesoft’s ESB,
so named because it aimed to remove the “donkey work” of integration:
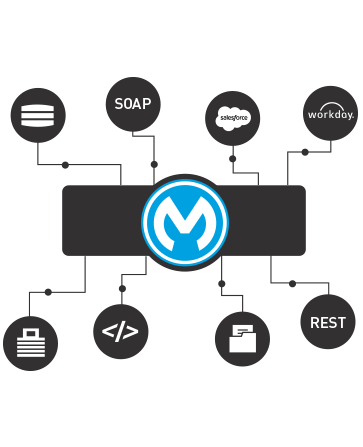
Figure 7: ESBs separate connectivity from orchestration
and routing
There were some natural false starts in the ESB world as the industry
aspired to have enterprise-wide canonical formats on the bus, but all of
them shared the notion of adapters to the inputs and outputs of the bus — the
systems being integrated. In the happy path, you could describe
your integration in a language like BPEL, which could provide a
graphical design palette and source-diagram isomorphism as it described
the process in XML.
The industry has largely moved on from ESBs, but you can see their
heritage in modern API platforms. Take a look, for example, at
Mulesoft’s three layer API architecture:
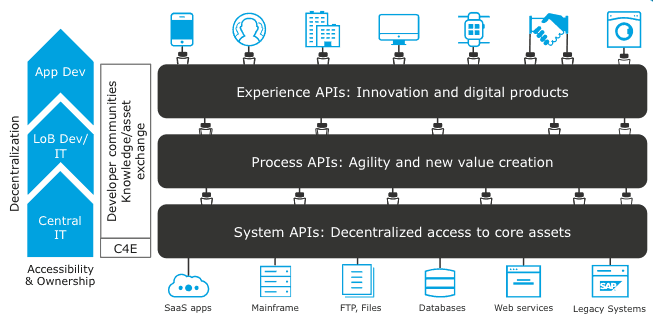
Figure 8: Mulesoft’s three layer architecture
maintains the separation of connectivity with experience and system APIs
Mulesoft sells both an API management platform and a low-code runtime
for building APIs. You can and often should buy middleware infrastructure, and it is
entirely possible to divorce the API gateway from the runtime, proxying
to APIs built in a general purpose programming language. If you do so,
the question arises: would you use Mulesoft’s three layer architecture
if you built all of the APIs outside the Mulesoft runtime?
I quite like the idea of experience APIs. The name is less jargony
than the one that’s caught on in the microservice
community — backends
for frontends — although I prefer the term “channel API” over both as
it more obviously covers a broader range of concerns. For example,
narrowing access to core APIs in a B2B scenario is clearly a channel
concern, less obviously an “experience” or “frontend” concern. Whatever
the name, providing an optimized channel-specific API is a valuable
pattern, one that allows the channel to evolve at a different rate than
the underlying capabilities and to narrow the surface area for
attackers.
I’m less excited about the prescriptive separation between process
and system APIs because of their focus on implementation over interface:
the system layer focuses on connectivity and the process layer focuses
on orchestration . I’ve redrawn their
simplified ESB picture above to show that the similarity on implementation
concerns to connect systems is hard to overlook:
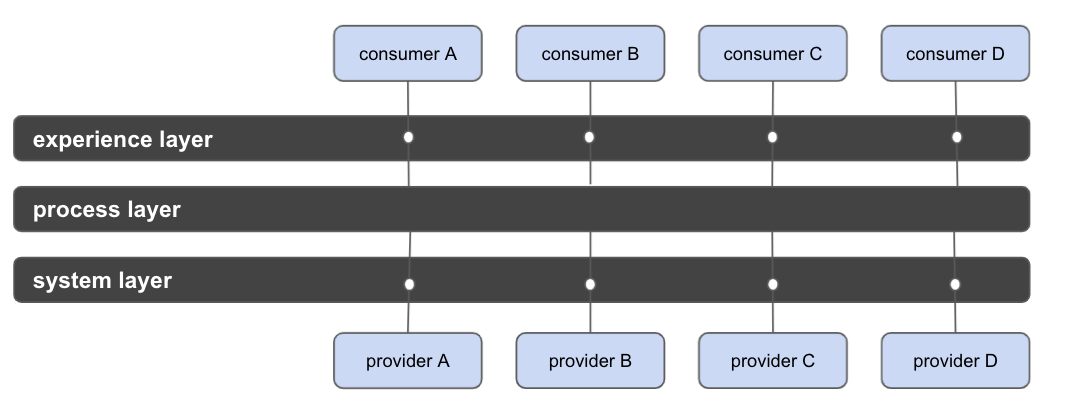
Figure 9: The three layer architecture emphasizes
implementation details, showing its ESB heritage
Part of the value proposition of a platform like Mulesoft — both its
ESB and API runtime — lies in the built in library of connectors to
systems like SAP and Salesforce, connectors that can save you time at
the edges of the system (especially the system layer). The three
layer architecture simplifies use of those connectors and separates
orchestration and aggregation to encourage their reuse.
Conceptually, the three layer architecture serves to constrain
designing APIs such that they fit inside Mulesoft’s ESB heritage. In
theory, the architecture allows more reuse across layers. In practice,
you are limited by programming-across-time concerns of evolving process
APIs to multiple consumers. In fact, I have seen many APIs that
are not APIs at all, but rather ETL in API clothing, with the system layer
managing the extract, the process layer managing the transform, and the
experience layer managing the load. That should not be surprising,
because integration tools think in terms of implementation.
The allure of buying integration tools is that they make the tactical
concern of wiring systems together cheaper, avoiding the usual expense and risk of
custom software. Unfortunately, when we frame the problem space that
way, we have allowed our tools to think for us.
Use commercial integration tools to simplify implementation concerns
As should be clear by now, I’m deeply skeptical of enterprise-wide
integration tool mandates, not because of any critique of the particular
tool itself, but because I believe the mandate represents a fundamental
misunderstanding of the value of integration. Tool vendors will push back
on that, of course, but tool vendors have a natural and understandable
goal of increasing penetration and lock-in. The role of the architect is
to ensure that you don’t let a vendor’s product strategy become your
architectural strategy, to create the appropriate
bounded context for the tool.
With that lens, I see at least two areas where commercial integration
DSLs can add tremendous value.
Simplifying workflow and connectivity
Just because implementation is a second order concern doesn’t mean
there isn’t real value in accelerating the implementation, as long as we
frame it appropriately behind an interface that simplifies access to the
underlying capability. Unsurprisingly, accelerating implementation is
precisely the main value proposition of commercial integration DSLs.
A number of integration DSLs are marketed to “own” the integration
landscape, and to call out to a general purpose language when necessary.
To address programming-over-time concerns, you’ll want to invert that
control, abstracting the parts of the implementation subject to
evolution complexity from those that are unlikely to require much change
over time.
One team I’ve interacted with uses Camunda
to manage microservices orchestration. Unlike some orchestration tools,
you can use Camunda as a Java library with Spring and Spring Boot integrations,
making it much easier to use traditional Java software engineering discipline to
manage the interface evolution in a general purpose programming language while
simplifying certain
implementation aspects with a workflow tool (open source, in this case,
but a commercial tool would have worked just as well)
Similarly, those system connectors and adapters can go a long way
towards providing some implementation lift, and can be abstracted behind
the core capability abstraction written in a general purpose programming
language. This is akin to Mulesoft’s system API guidance, which can be
good implementation advice even if your ultimate API strategy de-emphasizes
the systems. Similarly, graphical workflow
visualizations can accelerate wiring a series of calls together for simple
steps in a multi-step process, much
like the AWS Step Functions example shown above.
Generally speaking, I would be wary of adding much in the way of
transformations to the integration DSL, or I would at least be willing
to reimplement those transformations in a language like Java over time,
as that tends to be where a lot of programming-over-time complexity
lives. Transformations represent the buffer between data in the source systems
and the interface to that data that consuming systems expect, and therefore has
evolutionary pressure from multiple directions: changes in the system of record
as well as evolving the interface for consumers. Similarly, I would keep any
performance optimizations or resilience code (like caching) in a general purpose
language as they often become quite complex over time.
Capturing the long tail of B2B integrations
It is common in B2B scenarios to require integration outside
the walls of your organization. If you’re lucky, you can rely on clean
APIs for such integration, but luck isn’t a particularly rewarding
business strategy, and you may have to integrate with small
businesses with little IT capability. The combination of having to integrate
with systems as diverse as your B2B partners and dealing with some partners
with little to no IT capabilities provides a difficult challenge, a challenge
I’ve personally seen recur in three different industries:
- An energy company that transacts through distributors, and contracts
for shared sales information to manage automated stock
replenishment, - A heavy machinery retailer transacting with third party dealers, but
trying to globally optimize parts delivery, - A health care services firm transacting with payers, providing value
add-on services to detect (for example) fraud, waste, and abuse
Even when those B2B partners do have proper IT systems, the variety
can be overwhelming, and you may not have the leverage to ask them to
write integration to your API contract. Many B2B partners also exist in
legacy industries, slow to adopt new digital technologies. FTP file
transfers, EBCDIC conversions from mainframe systems, and EDI are still
concerns you may have to solve for.
The advantage of slow-moving IT is that programming-over-time
concerns are attenuated. The advantage of commercial integration DSLs is
that many of them likely do have capabilities to support the needed
integration patterns and transformations. Putting transformations
directly in the tool contradicts my advice above, but since B2B
integrations tend to move at the speed of lawyers and procurement
departments, the tradeoff is more attractive. You still want a
dedicated channel API, of course,
but the integration DSL can act as an inexpensive adapter.
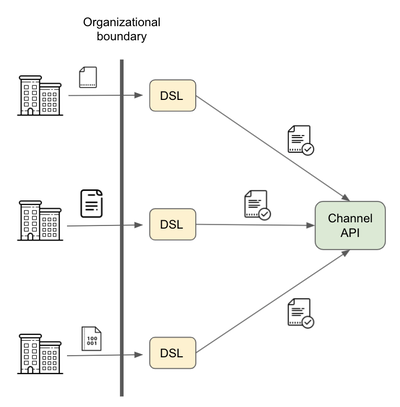
Figure 11: Use integration tools as adapters
between integration partners and a common channel API
Tackling the long tail of integration with a general purpose
programming language can be prohibitively expensive. Tackling it with
tools built to solve problems quickly as long as they don’t require
rapid evolution is likely a better economic decision.
Treat integration as strategic to your business
There is one reason I often hear used to justify buying integration
tools, often phrased as some variant of “we’re not a software company.”
The sentiment is understandable, meant to act as a principle to sort
through the difficult decision-making needed to prioritize investments
aligned with an organization’s overall value to the market. Developer
labor is a significant investment, and while there are many competent
developers comfortable with integration DSLs, at large, the labor market
for such developers is cheaper than the labor market for developers more
comfortable coding in general purpose languages.
I believe the principle very much falls into the “penny wise, pound
foolish” basket. After all, I suspect you’re not a math company either,
but at a certain scale you rely on some pretty advanced math skills. You
don’t solve that problem by buying a less powerful calculator for your
finance team and statisticians and asking them to break down the overall
problem into an approach that fits the complexity ceiling of the tool, of
turning every problem into a nail for your tool hammer.
Software is, of course, a different beast. Writing software is
notoriously risky and expensive, and many organizations are so afraid of
custom software that they go out of their way to avoid it. Buying a
graphical integration tool allows for a simpler, more approachable form of
custom software. Yes, it’s true that each line between boxes on your
architectural diagram will likely become simpler to create. However,
because of the complexity ceiling of such tools, the number of lines will
explode, which is like pouring slow-hardening concrete on your
architecture that increases your architectural tech debt over time.
A few years back I worked with a telecom that aspired to provide
self-service eCommerce capability to its users for new cell phone
purchases. Anyone who has ever worked in the industry understands the
challenges involved: buying telco services is fundamentally more
complicated than buying retail products because telco services have a
lifecycle. For cell phones, the usual customer-facing abstraction for that
lifecycle is the plan that details text, data, and voice limits, and how
international calls are billed (an enormously complex implementation
involving legal and carrier agreements, underwater cables, an entire
industry of deep sea cable repairs, and national defense agreements to
prevent severing cables, all hidden behind the clean interface of a phone
number).
There actually was an API already developed, but it had been developed
for the call center agents, not an eCommerce website. To get the available
plans for a phone, the API and underlying systems expected you first to
create a transaction that could log the call center agent’s actions — an
obviously incorrect abstraction for a website. We were able to work around
that limitation by creating a fake transaction only to receive an XML
payload full of system details:
<x:offerDetails>
<id>2207891</id>
<program>2205442</program>
<filter>
<typeCode>C</typeCode>
<subTypeCode>E</subTypeCode>
<contractTerm>24</contractTerm>
</filter>
</x:offerDetails>
Once we coordinated with various experts to understand what the magic
numbers and letters meant — leaky abstractions from the underlying
billing system — we still had one more call to get pricing details. That
final call returned over 1,000 lines of XML, of which about 100 were
relevant to our eCommerce needs.
Though it was by no means easy, we worked with the underlying IT
organization to create a new set of APIs that more clearly represented eCommerce
concerns without all the additional legacy complexity, clean interfaces that
translated the leaky abstractions into meaningful capabilities so that eCommerce
developers needed no understanding of the billing system mechanics. We had
to abstract the complexity of the legacy so that we could create the
future of self-service. The architecture diagrams reflected a new way of
thinking about the problem, of thinking in terms of digital capabilities
instead of underlying systems. We allowed neither downstream complexity nor implementation
programming languages to find a home in our diagramming for the eCommerce
team:
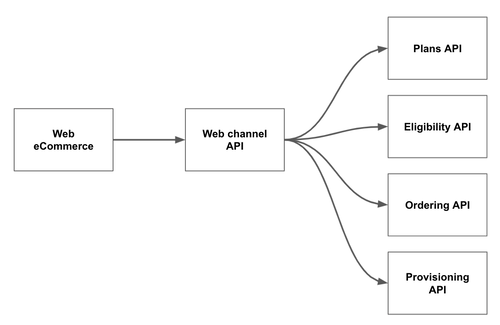
Figure 12: Despite significant downstream complexity,
we ensured clean interfaces to core capabilities to improve eCommerce
agility
When it was all said and done, that telco was the first to have a fully
automated self-service experience in their country when a new iPhone was
launched, beating out not just their direct competitors but mighty Apple
itself.
Whether apocryphal or not, the famous Jeff Bezos mandate to only
communicate through externalizable APIs may have been the key to their
current
world dominance. The mandate has far-reaching consequences, one of
which is to flip the integration conversation from thinking about
systems to thinking about capabilities, which created tremendous
organizational agility inside technology. The other, even more game
changing consequence was to generate revenue streams off of internal
operations — infrastructure provisioning, call centers, fulfillment — by
doing the hard work of simplifying the interface to consumers of those
capabilities independently of the expertise needed to run them. Doing so
created new boxes on their architecture diagrams, boxes where there used
to be lines, as they reified complex processes behind user-friendly
programmable interfaces.
Your integration strategy is the key architectural component to
organizational agility. It’s understandable to want to outsource it to a
product, similar to other buy versus build tradeoffs — to manage risk — but such
an approach will always lead to integration being treated as a tactical
concern. As Amazon has shown us, reframing the integration conversation
away from wiring systems together and towards exposing self-service
interfaces between business capabilities can lead to significant business
value. Doing so requires thinking in terms of the types of integration
principles explored in this article::
Principle
Description
Design your interface from your users’ perspective
Your APIs are themselves digital products, designed to
facilitate your developers and system integrators to tackle
complexity. As any product manager knows, a good product interface is
meant to make your users lives easier, not yours.
Abstract the capability, not the system
The underlying system is an implementation concern. Avoid leaky
abstractions and provide a simplified view of the underlying
capability.
Hide implementation complexity, even through evolution
Build abstractions that can evolve over time, even if that means
a more complicated implementation.
Create the future; adapt the past
Resist the temptation to expose the underlying complexity of
legacy integration to your consumers, as the alternative is forcing
each of your consumers to wrestle with the complexity with much less
contextual understanding of it than you.
Integration is strategic to your business
At scale, the only way to rationalize the complexity of your
business is to build simplifying abstractions behind clean interfaces.
In
The Software Architect Elevator, Gregor Hohpe described how digital
organizations operate in the “first derivative,” a math geek’s way of
saying that they shift their focus from their current digital footprint to
their rate of change. I’ll one-up Gregor and say that a good integration
strategy lives in the second derivative: your integration strategy, and
ability to invest the time and money to simplify the interfaces to your
organization’s capabilities, is a key driver of organizational
acceleration. It may slow you down at first by a small amount, but over
time, those interfaces become the gas pedal for your digital
transformation.
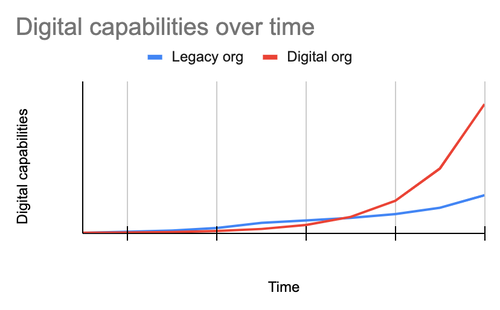
Figure 13: Building digital acceleration
requires paying attention to programming-over-time concerns, especially
the need for clean interfaces between systems
So by all means, buy your CRM and your revenue management system and
ML-driven sentiment analysis add-on to your call center. Buy your API
gateway and your analytics database and your container orchestration
system. Learn from the digital natives about product operating models and
insourcing approaches and autonomous team structures. Just remember that
none of it will make you competitive in a digital world if you continue to
treat integration as a tactical nuisance to overcome so you take advantage
of those new systems.
You can’t buy integration, but that’s OK; it’s worth the investment to
build it yourself. After all, it may be the most strategic software in
your portfolio.


{kind=link}