


A little background about this large bundle of essays: Students across the nation had originally written these essays between 2015 and 2019 as part of state standardized exams or classroom assessments. Their assignment had been to write an argumentative essay, such as “Should students be allowed to use cell phones in school?” The essays were collected to help scientists develop and test automated writing evaluation.
Each of the essays had been graded by expert raters of writing on a 1-to-6 point scale with 6 being the highest score. ETS asked GPT-4o to score them on the same six-point scale using the same scoring guide that the humans used. Neither man nor machine was told the race or ethnicity of the student, but researchers could see students’ demographic information in the datasets that accompany these essays.
GPT-4o marked the essays almost a point lower than the humans did. The average score across the 13,121 essays was 2.8 for GPT-4o and 3.7 for the humans. But Asian Americans were docked by an additional quarter point. Human evaluators gave Asian Americans a 4.3, on average, while GPT-4o gave them only a 3.2 – roughly a 1.1 point deduction. By contrast, the score difference between humans and GPT-4o was only about 0.9 points for white, Black and Hispanic students. Imagine an ice cream truck that kept shaving off an extra quarter scoop only from the cones of Asian American kids.
“Clearly, this doesn’t seem fair,” wrote Johnson and Zhang in an unpublished report they shared with me. Though the extra penalty for Asian Americans wasn’t terribly large, they said, it’s substantial enough that it shouldn’t be ignored.
The researchers don’t know why GPT-4o issued lower grades than humans, and why it gave an extra penalty to Asian Americans. Zhang and Johnson described the AI system as a “huge black box” of algorithms that operate in ways “not fully understood by their own developers.” That inability to explain a student’s grade on a writing assignment makes the systems especially frustrating to use in schools.
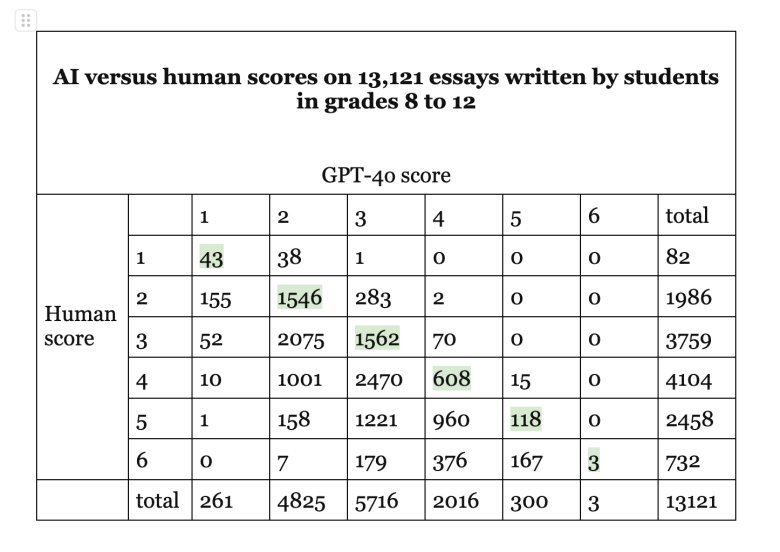
This one study isn’t proof that AI is consistently underrating essays or biased against Asian Americans. Other versions of AI sometimes produce different results. A separate analysis of essay scoring by researchers from University of California, Irvine and Arizona State University found that AI essay grades were just as frequently too high as they were too low. That study, which used the 3.5 version of ChatGPT, did not scrutinize results by race and ethnicity.
I wondered if AI bias against Asian Americans was somehow connected to high achievement. Just as Asian Americans tend to score high on math and reading tests, Asian Americans, on average, were the strongest writers in this bundle of 13,000 essays. Even with the penalty, Asian Americans still had the highest essay scores, well above those of white, Black, Hispanic, Native American or multi-racial students.
In both the ETS and UC-ASU essay studies, AI awarded far fewer perfect scores than humans did. For example, in this ETS study, humans awarded 732 perfect 6s, while GPT-4o gave out a grand total of only three. GPT’s stinginess with perfect scores might have affected a lot of Asian Americans who had received 6s from human raters.
ETS’s researchers had asked GPT-4o to score the essays cold, without showing the chatbot any graded examples to calibrate its scores. It’s possible that a few sample essays or small tweaks to the grading instructions, or prompts, given to ChatGPT could reduce or eliminate the bias against Asian Americans. Perhaps the robot would be fairer to Asian Americans if it were explicitly prompted to “give out more perfect 6s.”
The ETS researchers told me this wasn’t the first time that they’ve noticed Asian students treated differently by a robo-grader. Older automated essay graders, which used different algorithms, have sometimes done the opposite, giving Asians higher marks than human raters did. For example, an ETS automated scoring system developed more than a decade ago, called e-rater, tended to inflate scores for students from Korea, China, Taiwan and Hong Kong on their essays for the Test of English as a Foreign Language (TOEFL), according to a study published in 2012. That may have been because some Asian students had memorized well-structured paragraphs, while humans easily noticed that the essays were off-topic. (The ETS website says it only relies on the e-rater score alone for practice tests, and uses it in conjunction with human scores for actual exams.)
Asian Americans also garnered higher marks from an automated scoring system created during a coding competition in 2021 and powered by BERT, which had been the most advanced algorithm before the current generation of large language models, such as GPT. Computer scientists put their experimental robo-grader through a series of tests and discovered that it gave higher scores than humans did to Asian Americans’ open-response answers on a reading comprehension test.
It was also unclear why BERT sometimes treated Asian Americans differently. But it illustrates how important it is to test these systems before we unleash them in schools. Based on educator enthusiasm, however, I fear this train has already left the station. In recent webinars, I’ve seen many teachers post in the chat window that they’re already using ChatGPT, Claude and other AI-powered apps to grade writing. That might be a time saver for teachers, but it could also be harming students.


{kind=link}