


A common feature of legacy systems is the Critical Aggregator,
as the name implies this produces information vital to the running of a
business and thus cannot be disrupted. However in legacy this pattern
almost always devolves to an invasive highly coupled implementation,
effectively freezing itself and upstream systems into place.
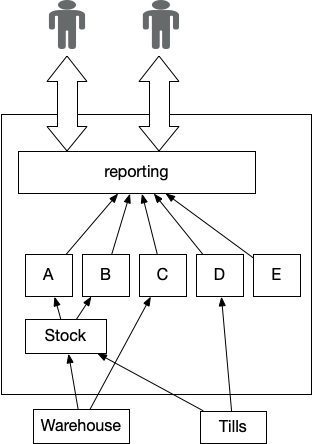
Figure 1: Reporting Critical Aggregator
Divert the Flow is a strategy that starts a Legacy Displacement initiative
by creating a new implementation of the Critical Aggregator
that, as far as possible, is decoupled from the upstream systems that
are the sources of the data it needs to operate. Once this new implementation
is in place we can disable the legacy implementation and hence have
far more freedom to change or relocate the various upstream data sources.
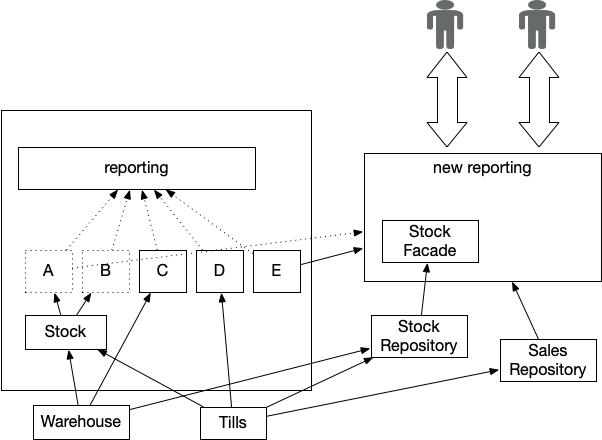
Figure 2: Extracted Critical Aggregator
The alternative displacement approach when we have a Critical Aggregator
in place is to leave it until last. We can displace the
upstream systems, but we need to use Legacy Mimic to
ensure the aggregator within legacy continues to receive the data it
needs.
Either option requires the use of a Transitional Architecture, with
temporary components and integrations required during the displacement
effort to either support the Aggregator remaining in place, or to feed data to the new
implementation.
How It Works
Diverting the Flow creates a new implementation of a cross cutting
capability, in this example that being a Critical Aggregator.
Initially this implementation might receive data from
existing legacy systems, for example by using the
Event Interception pattern. Alternatively it might be simpler
and more valuable to get data from source systems themselves via
Revert to Source. In practice we tend to see a
combination of both approaches.
The Aggregator will change the data sources it uses as existing upstream systems
and components are themselves displaced from legacy,
thus it’s dependency on legacy is reduced over time.
Our new Aggregator
implementation can also take advantage of opportunities to improve the format,
quality and timeliness of data
as source systems are migrated to new implementations.
Map data sources
If we are going to extract and re-implement a Critical Aggregator
we first need to understand how it is linked to the rest of the legacy
estate. This means analyzing and understanding
the ultimate source of data used for the aggregation. It is important
to remember here that we need to get to the ultimate upstream system.
For example
while we might treat a mainframe, say, as the source of truth for sales
information, the data itself might originate in in-store till systems.
Creating a diagram showing the
aggregator alongside the upstream and downstream dependencies
is key.
A system context diagram, or similar, can work well here; we have to ensure we
understand exactly what data is flowing from which systems and how
often. It’s common for legacy solutions to be
a data bottleneck: additional useful data from (newer) source systems is
often discarded as it was too difficult to capture or represent
in legacy. Given this we also need to capture which upstream source
data is being discarded and where.
User requirements
Obviously we need to understand how the capability we plan to “divert”
is used by end users. For Critical Aggregator we often
have a very large mix of users for each report or metric. This is a
classic example of where Feature Parity can lead
to rebuilding a set of “bloated” reports that really don’t meet current
user needs. A simplified set of smaller reports and dashboards might
be a better solution.
Parallel running might be necessary to ensure that key numbers match up
during the initial implementation,
allowing the business to satisfy themselves things work as expected.
Capture how outputs are produced
Ideally we want to capture how current outputs are produced.
One technique is to use a sequence diagram to document the order of
data reception and processing in the legacy system, or even just a
flow chart.
However there are
often diminishing returns in trying to fully capture the existing
implementation, it not unusual to find that key knowledge has been
lost. In some cases the legacy code might be the only
“documentation” for how things work and understanding this might be
very difficult or costly.
One author worked with a client who used an export
from a legacy system alongside a highly complex spreadsheet to perform
a key financial calculation. No one currently at the organization knew
how this worked, luckily we were put in touch with a recently retired
employee. Unfortunately when we spoke to them it turned out they’d
inherited the spreadsheet from a previous employee a decade earlier,
and sadly this person had passed away some years ago. Reverse engineering the
legacy report and (twice ‘version migrated’) excel spreadsheet was more
work than going back to first principles and defining from fresh what
the calculation should do.
While we may not be building to feature parity in the
replacement end point we still need key outputs to ‘agree’ with legacy.
Using our aggregation example we might
now be able to produce hourly sales reports for stores, however business
leaders still
need the end of month totals and these need to correlate with any
existing numbers.
We need to work with end users to create worked examples
of expected outputs for given test inputs, this can be vital for spotting
which system, old or new, is ‘correct’ later on.
Delivery and Testing
We’ve found this pattern lends itself well to an iterative approach
where we build out the new functionality in slices. With Critical
Aggregator
this means delivering each report in turn, taking them all the way
through to a production like environment. We can then use
Parallel Running
to monitor the delivered reports as we build out the remaining ones, in
addition to having beta users giving early feedback.
Our experience is that many legacy reports contain undiscovered issues
and bugs. This means the new outputs rarely, if ever, match the existing
ones. If we don’t understand the legacy implementation fully it’s often
very hard to understand the cause of the mismatch.
One mitigation is to use automated testing to inject known data and
validate outputs throughout the implementation phase. Ideally we’d
do this with both new and legacy implementations so we can compare
outputs for the same set of known inputs. In practice however due to
availability of legacy test environments and complexity of injecting data
we often just do this for the new system, which is our recommended
minimum.
It’s common to find “off system” workarounds in legacy aggregation,
clearly it’s important to try and track these down during migration
work.
The most common example is where the reports
needed by the leadership team are not actually available from the legacy
implementation, so someone manually manipulates the reports to create
the actual outputs they
see – this often takes days. As no-one wants to tell leadership the
reporting doesn’t actually work they often remain unaware this is
how really things work.
Go Live
Once we are happy functionality in the new aggregator is correct we can divert
users towards the new solution, this can be done in a staged fashion.
This might mean implementing reports for key cohorts of users,
a period of parallel running and finally cutting over to them using the
new reports only.
Monitoring and Alerting
Having the correct automated monitoring and alerting in place is vital
for Divert the Flow, especially when dependencies are still in legacy
systems. You need to monitor that updates are being received as expected,
are within known good bounds and also that end results are within
tolerance. Doing this checking manually can quickly become a lot of work
and can create a source of error and delay going forwards.
In general we recommend fixing any data issues found in the upstream systems
as we want to avoid re-introducing past workarounds into our
new solution. As an extra safety measure we can leave the Parallel Running
in place for a period and with selective use of reconciliation tools, generate an alert if the old and new
implementations start to diverge too far.
When to Use It
This pattern is most useful when we have cross cutting functionality
in a legacy system that in turn has “upstream” dependencies on other parts
of the legacy estate. Critical Aggregator is the most common example. As
more and more functionality gets added over time these implementations can become
not only business critical but also large and complex.
An often used approach to this situation is to leave migrating these “aggregators”
until last since clearly they have complex dependencies on other areas of the
legacy estate.
Doing so creates a requirement to keep legacy updated with data and events
once we being the process of extracting the upstream components. In turn this
means that until we migrate the “aggregator” itself these new components remain
to some degree
coupled to legacy data structures and update frequencies. We also have a large
(and often important) set of users who see no improvements at all until near
the end of the overall migration effort.
Diverting the Flow offers an alternative to this “leave until the end” approach,
it can be especially useful where the cost and complexity of continuing to
feed the legacy aggregator is significant, or where corresponding business
process changes means reports, say, need to be modified and adapted during
migration.
Improvements in update frequency and timeliness of data are often key
requirements for legacy modernisation
projects. Diverting the Flow gives an opportunity to deliver
improvements to these areas early on in a migration project,
especially if we can apply
Revert to Source.
Data Warehouses
We often come across the requirement to “support the Data Warehouse”
during a legacy migration as this is the place where key reports (or similar) are
actually generated. If it turns out the DWH is itself a legacy system then
we can “Divert the Flow” of data from the DHW to some new better solution.
While it can be possible to have new systems provide an identical feed
into the warehouse care is needed as in practice we are once again coupling our new systems
to the legacy data format along with it’s attendant compromises, workarounds and, very importantly,
update frequencies. We have
seen organizations replace significant portions of legacy estate but still be stuck
running a business on out of date data due to dependencies and challenges with their DHW
solution.



{kind=link}