


Every startup’s journey is unique, and the road to success is never
linear, but cost is a narrative in every business at every point in time,
especially during economic downturns. In a startup, the conversation around
cost shifts when moving from the experimental and gaining traction
phases to high growth and optimizing phases. In the first two phases, a
startup needs to operate lean and fast to come to a product-market fit, but
in the later stages the importance of operational efficiency eventually
grows.
Shifting the company’s mindset into achieving and maintaining cost
efficiency is really difficult. For startup engineers that thrive
on building something new, cost optimization is typically not an exciting
topic. For those reasons, cost efficiency often becomes a bottleneck for
startups at some point in their journey, just like accumulation of technical
debt.
How did you get into the bottleneck?
In the early experimental phase of startups, when funding is limited,
whether bootstrapped by founders or supported by seed investment, startups
generally focus on getting market traction before they run out of their
financial runway. Teams will pick solutions that get the product to market
quickly so the company can generate revenue, keep users happy, and
outperform competitors.
In these phases, cost inefficiency is an acceptable trade-off.
Engineers may choose to go with quick custom code instead of dealing with
the hassle of setting up a contract with a SaaS provider. They may
deprioritize cleanups of infrastructure components that are no longer
needed, or not tag resources as the organization is 20-people strong and
everyone knows everything. Getting to market quickly is paramount – after
all, the startup might not be there tomorrow if product-market fit remains
elusive.
After seeing some success with the product and reaching a rapid growth
phase, those previous decisions can come back to hurt the company. With
traffic spiking, cloud costs surge beyond anticipated levels. Managers
know the company’s cloud costs are high, but they may have trouble
pinpointing the cause and guiding their teams to get out of the
situation.
At this point, costs are starting to be a bottleneck for the business.
The CFO is noticing, and the engineering team is getting a lot of
scrutiny. At the same time, in preparation for another funding round, the
company would need to show reasonable COGS (Cost of Goods Sold).
None of the early decisions were wrong. Creating a perfectly scalable
and cost efficient product is not the right priority when market traction
for the product is unknown. The question at this point, when cost starts
becoming a problem, is how to start to reduce costs and change the
company culture to sustain the improved operational cost efficiency. These
changes will ensure the continued growth of the startup.
Signs you are approaching a scaling bottleneck
Lack of cost visibility and attribution
When a company uses multiple service providers (cloud, SaaS,
development tools, etc.), the usage and cost data of these services
lives in disparate systems. Making sense of the total technology cost
for a service, product, or team requires pulling this data from various
sources and linking the cost to their product or feature set.
These cost reports (such as cloud billing reports) can be
overwhelming. Consolidating and making them easily understandable is
quite an effort. Without proper cloud infrastructure tagging
conventions, it is impossible to properly attribute costs to specific
aggregates at the service or team level. However, unless this level of
accounting clarity is enabled, teams will be forced to operate without
fully understanding the cost implications of their decisions.
Cost not a consideration in engineering solutions
Engineers consider various factors when making engineering decisions
– functional and non-functional requirements (performance, scalability
and security etc). Cost, however, is not always considered. Part of the
reason, as covered above, is that development teams often lack
visibility on cost. In some cases, while they have a reasonable level of
visibility on the cost of their part of the tech landscape, cost may not
be perceived as a key consideration, or may be seen as another team’s
concern.
Signs of this problem might be the lack of cost considerations
mentioned in design documents / RFCs / ADRs, or whether an engineering
manager can show how the cost of their products will change with scale.
Homegrown non-differentiating capabilities
Companies sometimes maintain custom tools that have major overlaps in
capabilities with third-party tools, whether open-source or commercial.
This may have happened because the custom tools predate those
third-party solutions – for example, custom container orchestration
tools before Kubernetes came along. It could also have grown from an
early initial shortcut to implement a subset of capability provided by
mature external tools. Over time, individual decisions to incrementally
build on that early shortcut lead the team past the tipping point that
might have led to utilizing an external tool.
Over the long term, the total cost of ownership of such homegrown
systems can become prohibitive. Homegrown systems are typically very
easy to start and quite difficult to master.
Overlapping capabilities in multiple tools / tool explosion
Having multiple tools with the same purpose – or at least overlapping
purposes, e.g. multiple CI/CD pipeline tools or API observability tools,
can naturally create cost inefficiencies. This often comes about when
there isn’t a paved
road,
and each team is autonomously picking their technical stack, rather than
choosing tools that are already licensed or preferred by the company.
Inefficient contract structure for managed services
Choosing managed services for non-differentiating capabilities, such
as SMS/email, observability, payments, or authorization can greatly
support a startup’s pursuit to get their product to market quickly and
keep operational complexity in check.
Managed service providers often provide compelling – cheap or free –
starter plans for their services. These pricing models, however, can get
expensive more quickly than anticipated. Cheap starter plans aside, the
pricing model negotiated initially may not suit the startup’s current or
projected usage. Something that worked for a small organization with few
customers and engineers might become too expensive when it grows to 5x
or 10x those numbers. An escalating trend in the cost of a managed
service per user (be it employees or customers) as the company achieves
scaling milestones is a sign of a growing inefficiency.
Unable to reach economies of scale
In any architecture, the cost is correlated to the number of
requests, transactions, users using the product, or a combination of
them. As the product gains market traction and matures, companies hope
to gain economies of scale, reducing the average cost to serve each user
or request (unit
cost)
as its user base and traffic grows. If a company is having trouble
achieving economies of scale, its unit cost would instead increase.
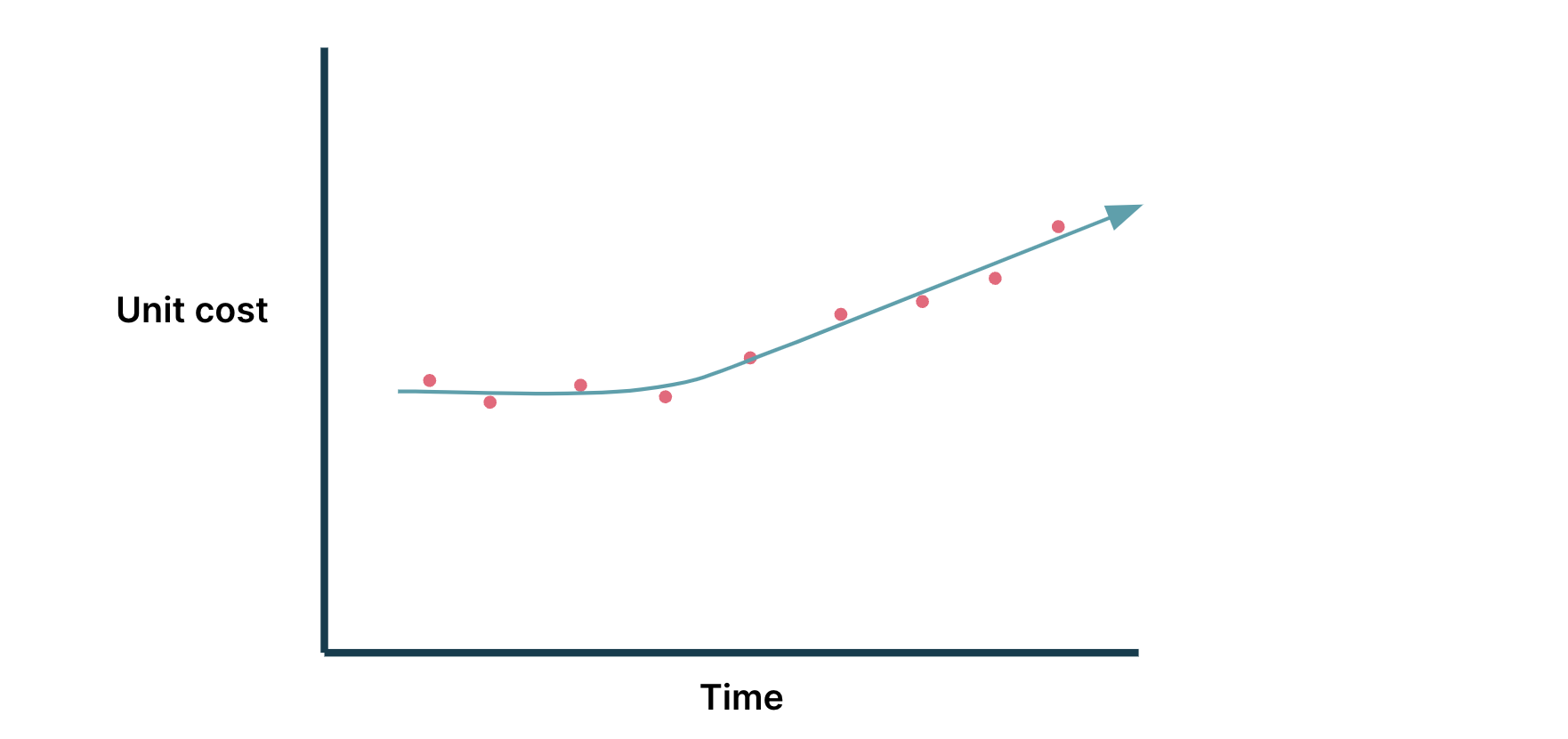
Figure 1: Not reaching economies of scale: increasing unit cost
Note: in this example diagram, it is implied that there are more
units (requests, transactions, users as time progresses)
How do you get out of the bottleneck?
A normal scenario for our team when we optimize a scaleup, is that
the company has noticed the bottleneck either by monitoring the signs
mentioned above, or it’s just plain obvious (the planned budget was
completely blown). This triggers an initiative to improve cost
efficiency. Our team likes to organize the initiative around two phases,
a reduce and a sustain phase.
The reduce phase is focused on short term wins – “stopping the
bleeding”. To do this, we need to create a multi-disciplined cost
optimization team. There may be some idea of what is possible to
optimize, but it is necessary to dig deeper to really understand. After
the initial opportunity analysis, the team defines the approach,
prioritizes based on the impact and effort, and then optimizes.
After the short-term gains in the reduce phase, a properly executed
sustain phase is critical to maintain optimized cost levels so that
the startup does not have this problem again in the future. To support
this, the company’s operating model and practices are adapted to improve
accountability and ownership around cost, so that product and platform
teams have the necessary tools and information to continue
optimizing.
To illustrate the reduce and sustain phased approach, we will
describe a recent cost optimization undertaking.
Case study: Databricks cost optimization
A client of ours reached out as their costs were increasing
more than they expected. They had already identified Databricks costs as
a top cost driver for them and requested that we help optimize the cost
of their data infrastructure. Urgency was high – the increasing cost was
starting to eat into their other budget categories and growing
still.
After initial analysis, we quickly formed our cost optimization team
and charged them with a goal of reducing cost by ~25% relative to the
chosen baseline.
The “Reduce” phase
With Databricks as the focus area, we enumerated all the ways we
could impact and manage costs. At a high level, Databricks cost
consists of virtual machine cost paid to the cloud provider for the
underlying compute capability and cost paid to Databricks (Databricks
Unit cost / DBU).
Each of these cost categories has its own levers – for example, DBU
cost can change depending on cluster type (ephemeral job clusters are
cheaper), purchase commitments (Databricks Commit Units / DBCUs), or
optimizing the runtime of the workload that runs on it.
As we were tasked to “save cost yesterday”, we went in search of
quick wins. We prioritized those levers against their potential impact
on cost and their effort level. As the transformation logic in the
data pipelines are owned by respective product teams and our working
group did not have a good handle on them, infrastructure-level changes
such as cluster rightsizing, using ephemeral clusters where
appropriate, and experimenting with Photon
runtime
had lower effort estimates compared to optimization of the
transformation logic.
We started executing on the low-hanging fruits, collaborating with
the respective product teams. As we progressed, we monitored the cost
impact of our actions every 2 weeks to see if our cost impact
projections were holding up, or if we needed to adjust our priorities.
The savings added up. A few months in, we exceeded our goal of ~25%
cost savings monthly against the chosen baseline.
The “Sustain” phase
However, we did not want cost savings in areas we had optimized to
creep back up when we turned our attention to other areas still to be
optimized. The tactical steps we took had reduced cost, but sustaining
the lower spending required continued attention due to a real risk –
every engineer was a Databricks workspace administrator capable of
creating clusters with any configuration they choose, and teams were
not monitoring how much their workspaces cost. They were not held
accountable for those costs either.
To address this, we set out to do two things: tighten access
control and improve cost awareness and accountability.
To tighten access control, we limited administrative access to just
the people who needed it. We also used Databricks cluster policies to
limit the cluster configuration options engineers can pick – we wanted
to achieve a balance between allowing engineers to make changes to
their clusters and limiting their choices to a sensible set of
options. This allowed us to minimize overprovisioning and control
costs.
To improve cost awareness and accountability, we configured budget
alerts to be sent out to the owners of respective workspaces if a
particular month’s cost exceeds the predetermined threshold for that
workspace.
Both phases were key to reaching and sustaining our objectives. The
savings we achieved in the reduced phase stayed stable for a number of
months, save for completely new workloads.


{kind=link}