


Business Leaders often need to make decisions that are influenced by a
wide range of activity throughout the whole enterprise.
For example a manufacturer understanding sales
margins might require information about the cost of raw materials,
operating costs of manufacturing facilities, sales levels and prices.
The right information, aggregated by region, market, or for the entire
organization needs to be available in a comprehensible form.
A Critical Aggregator is a software component that knows which systems to
“visit” to extract this information, which files/tables/APIs to inspect,
how to relate information from different sources, and the business logic
needed to aggregate this data.
It provides this information to business leaders through printed tables,
a dashboard with charts and tables, or a data feed that goes into
consumers’ spreadsheets.
By their very nature these reports involve pulling data from many different
parts of a business, for example financial data, sales data, customer data
and so on. When implemented using good practices such as encapsulation
and separation of concerns this doesn’t create any particular architectural
challenge. However we often see specific issues when this requirement is
implemented on top of legacy systems, especially monolithic mainframes or
data warehouses.
Within legacy the implementation of this pattern almost always takes advantage
of being able to reach directly into sub-components to fetch the data it
needs during processing. This sets up a particularly nasty coupling,
as upstream systems are then unable to evolve their data structures due
to the risk of breaking the now Invasive Critical Aggregator .
The consequence of such a failure being particularly high,
and visible, due to its critical role in supporting the business and it’s
leaders.
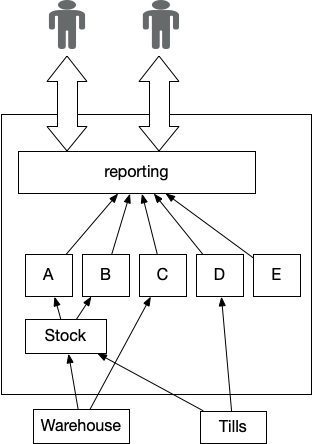
Figure 1: Reporting using Pervasive Aggregator
How It Works
Firstly we define what
input data is required to produce a output, such as a report. Usually the
source data is already present within components of the overall architecture.
We then create an implementation to “load” in the source data and process
it to create our output. Key here is to ensure we don’t create
a tight coupling to the structure of the source data, or break encapsulation
of an existing component to reach the data we need. At a database level this
might be achieved via ETL (Extract, Transform, Load), or via an API at
the service level. It is worth noting that ETL approaches often become
coupled to either the source or destination format; longer term this can
become a barrier to change.
The processing may be done record-by-record, but for more complex scenarios
intermediate state might be needed, with the next step in processing being
triggered once this intermediate data is ready.
Thus many implementations use a Pipeline, a series of
Pipes and Filters,
with the output of one step becoming an input for the next step.
The timeliness of the data is a key consideration, we need to make sure
we use source data at the correct times, for example after the end
of a trading day. This can create timing dependencies between the aggregator
and the source systems.
One approach is to trigger things at specific times,
although this approach is vulnerable to delays in any source system.
e.g. run the aggregator at 3am, however should there be a delay in any
source systems the aggregated results might be based on stale or corrupt data.
Another
more robust approach is to have source systems send or publish the source data
once it is ready, with the aggregator being triggered once all data is
available. In this case the aggregated results are delayed but should
at least be based upon valid input data.
We can also ensure source data is timestamped although this relies
on the source systems already having the correct time data available or being easy
to change, which might not be the case for legacy systems. If timestamped
data is available we can apply more advanced processing to ensure
consistent and valid results, such as
Versioned Value.
When to Use It
This pattern is used when we have a genuine need to get an overall
view across many different parts or domains within a business, usually
when we need to correlate data from different domains into a summary
view or set of metrics that are used for decision support.
Legacy Manifestation
Given past limitations on network bandwidth and I/O speeds it often made
sense to co-locate data processing on the same machine as the data storage.
High volumes of data storage with reasonable access times often
required specialized hardware, this led to centralized data storage
solutions. These two forces together combined to make many legacy
implementations of this pattern tightly coupled to source data structures,
dependent on data update schedules and timings, with implementations often
on the same hardware as the data storage.
The resulting Invasive Critical Aggregator puts its
roots into many different parts of
the overall system – thus making it very challenging to extract.
Broadly speaking there are two approaches to displacement. The
first approach is to create a new implementation of Critical Aggregator,
which can be done by Divert the Flow, combined with other patterns
such as Revert to Source. The alternative, more common approach, is to leave
the aggregator in place but use techniques such a Legacy Mimic to provide
the required data throughout displacement. Obviously a new implementation
is needed eventually.
Challenges with Invasive Critical Aggregator
Most legacy implementations of Critical Aggregator are characterized
by the lack of encapsulation around the source
data, with any processing directly dependent on the structure and
form of the various source data formats. They also have poor separation of
concerns with Processing and Data Access code intermingled. Most implementations
are written in batch data processing languages.
The anti-pattern is characterized by a high amount of coupling
within a system, especially as implementations reach directly into source data without any
encapsulation. Thus any change to the source data structure will immediately
impact the processing and outputs. A common approach to this problem is
to freeze source data formats or to add a change control process on
all source data. This change control process can become highly complex especially
when large hierarchies of source data and systems are present.
Invasive Critical Aggregator also tends to scale poorly as data volume grows since the lack
of encapsulation makes introduction of any optimization or parallel processing
problematic, we see
execution time tending to grow with data volumes. As the processing and
data access mechanisms are coupled together this can lead to a need to
vertically scale an entire system. This is a very expensive way to scale
processing that in a better encapsulated system could
be done by commodity hardware separate from any data storage.
Invasive Critical Aggregator tends to be susceptible to timing issues. Late update
of source data might delay aggregation or cause it to run on stale data,
given the critical nature of the aggregated reports this can cause serious
issues for a business.
The direct access to the source data during
processing means implementations usually have a defined “safe time window”
where source data must be up-to-date while remaining stable and unchanging.
These time windows are not usually enforced by the system(s)
but instead are often a convention, documented elsewhere.
As processing duration grows this can create timing constraints for the systems
that produce the source data. If we have a fixed time the final output
must be ready then any increase in processing time in turn means any source data must
be up-to-date and stable earlier.
These various timing constraints make incorporating data
from different time zones problematic as any overnight “safe time window”
might start to overlap with normal working hours elsewhere in the world.
Timing and triggering issues are a very common source of error and bugs
with this pattern, these can be challenging to diagnose.
Modification and testing is also challenging due to the poor separation of
concerns between processing and source data access. Over time this code grows
to incorporate workarounds for bugs, source data format changes, plus any new
features. We typically find most legacy implementations of the Critical Aggregator are in a “frozen” state due to these challenges alongside the business
risk of the data being wrong. Due to the tight coupling any change
freeze tends to spread to the source data and hence corresponding source systems.
We also tend to see ‘bloating’ outputs for the aggregator, since given the
above issues it is
often simpler to extend an existing report to add a new piece of data than
to create a brand new report. This increases the implementation size and
complexity, as well as the business critical nature of each report.
It can also make replacement harder as we first need to break down each use
of the aggregator’s outputs to discover if there are separate users
cohorts whose needs could be met with simpler more targeted outputs.
It is common to see implementations of this (anti-)pattern in COBOL and assembler
languages, this demonstrates both the difficulty in replacement but
also how critical the outputs can be for a business.


{kind=link}